
I am a Ph.D. student at POSTECH, advised by Tae-Hyun Oh. I am also a research scientist intern at Sony AI, advised by Yuhta Takida and Toshimitsu Uesaka. I received my bachelor’s degrees in Physics and Electrical Engineering (Double major) from Chung-Ang University. I work on research projects at the intersection of computer vision and machine learning, with a focus on modalities that contain temporal information, such as video and audio.
My research interests are on multi-modal learning, especially within audio-visual understanding and generation, but not limited to.
🔥 News
- 2026.02: One paper has been accepted to CVPR 2026.
- 2025.07: I’ll start a research scientist internship at Sony AI, Tokyo.
- 2025.02: One paper has been accepted to CVPR 2025 Highlight (Top 3.7%).
- 2025.01: One paper has been accepted to ICLR 2025.
- 2024.07: One paper has been accepted to ECCV 2024.
- 2024.06: Two papers have been accepted to INTERSPEECH 2024.
- 2024.04: One paper has been accepted to RA-L 2024. This will be presented in IROS 2024 (Oral presentation).
📝 Pre-print
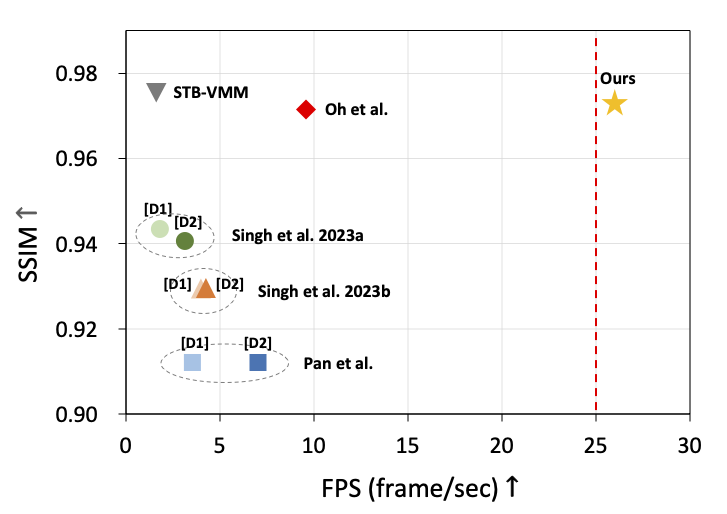
[P1] Revisiting Learning-based Video Motion Magnification for Real-time Processing (under-review)
Hyunwoo Ha*, Oh Hyun-Bin*, Kim Jun-Seong, Kwon Byung-Ki, Kim Sung-Bin, Linh-Tam Tran, Ji-Yun Kim, Sung-Ho Bae, Tae-Hyun Oh (*: equal contribution)
Project
- We magnify invisible small motions, but in real-time.
- Short version at CVPRW 2023 ‘Vision-based InduStrial InspectiON’ Workshop.
📝 Publications
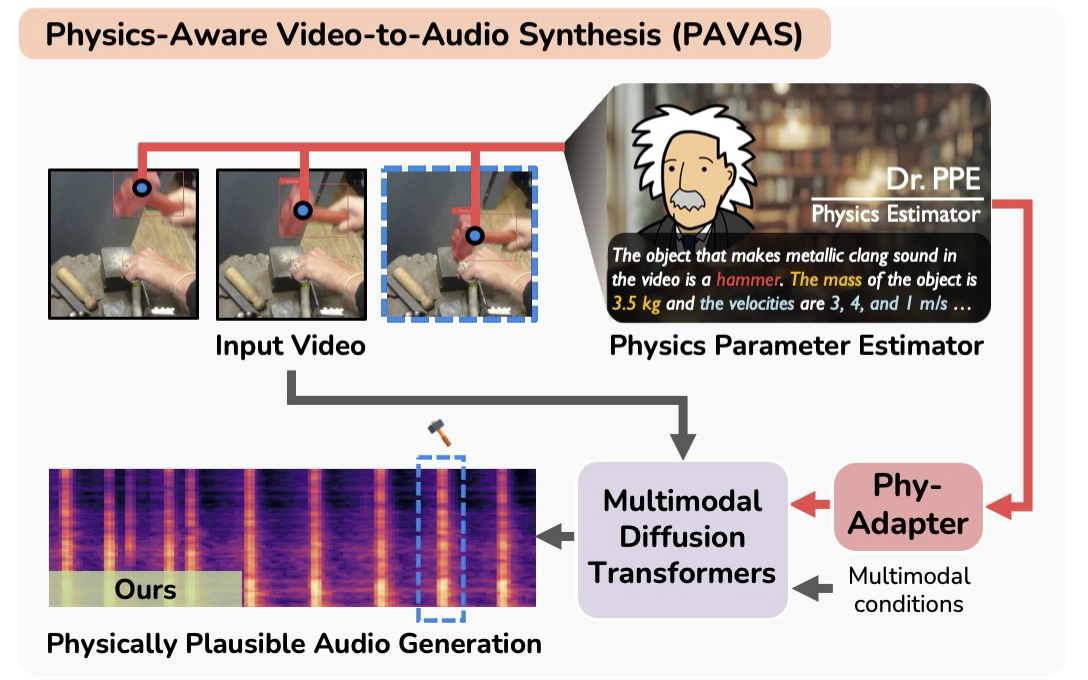
[C6] PAVAS: Physics-Aware Video-to-Audio Synthesis
Oh Hyun-Bin, Yuhta Takida, Toshimitsu Uesaka, Tae-Hyun Oh, Yuki Mitsufuji
- We generate a physically plausible audio from a video, by explicitly integrating physics estimation into a latent diffusion-based model.
- Work done during an internship at Sony AI.
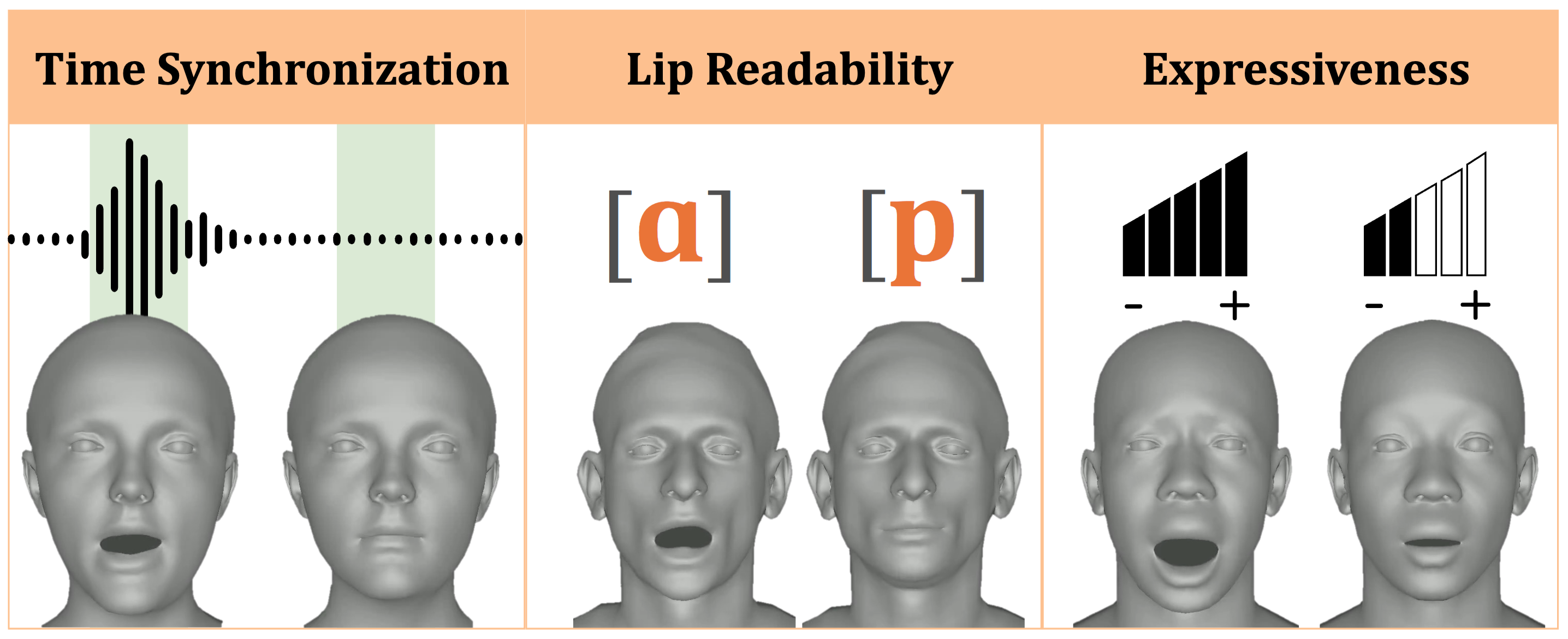
Lee Chae-Yeon*, Oh Hyun-Bin*, Han EunGi, Kim Sung-Bin, Suekyeong Nam, Tae-Hyun Oh (*: equal contribution)
- We introduce novel definitions, a speech-mesh representation space, and evaluation metrics for perceptually accurate 3D talking face generation.
- Selected as a highlight (top 3.7%) with all strong accept 5,5,5 scores .
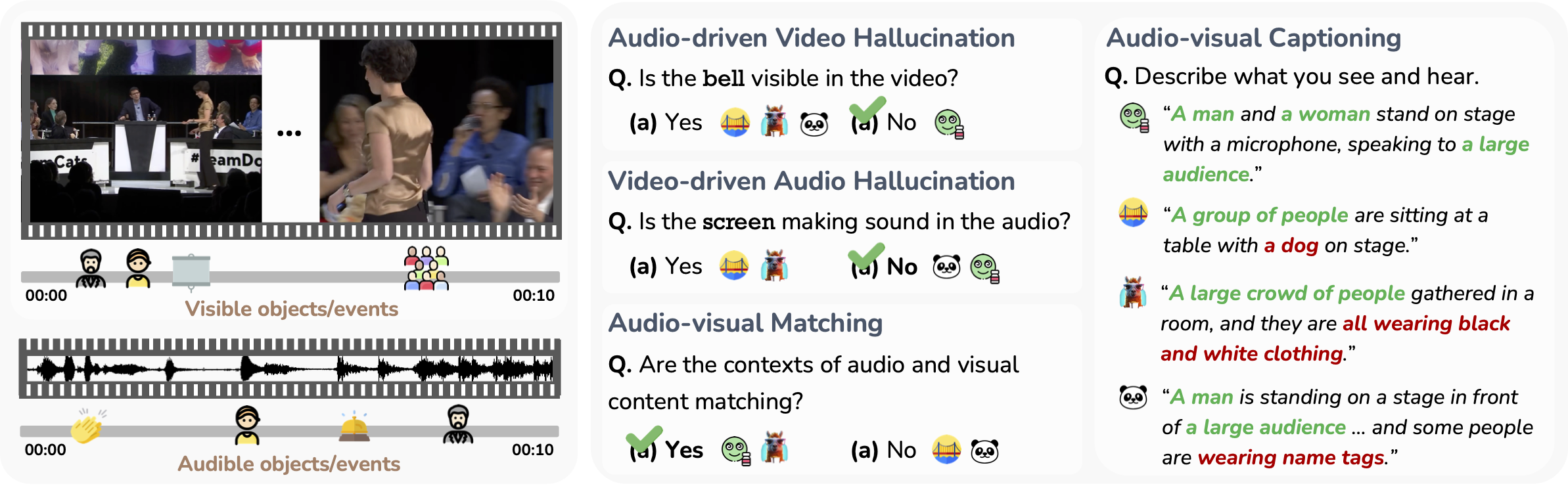
[C4] AVHBench: A Cross-Modal Hallucination Evluation for Audio-Visual Large Language Models
Kim Sung-Bin*, Oh Hyun-Bin*, JungMok Lee, Arda Senocak, Joon Son Chung, Tae-Hyun Oh (*: equal contribution)
- We introduce a comprehensive benchmark specifically designed to evaluate the perception and comprehension capabilities of audio-visual LLMs.

[C3] Learning-based Axial Video Motion Magnification
Kwon Byung-Ki, Oh Hyun-Bin, Kim Jun-Seong, Hyunwoo Ha, Tae-Hyun Oh
- We magnify invisible small motions, but in user-specified directions.
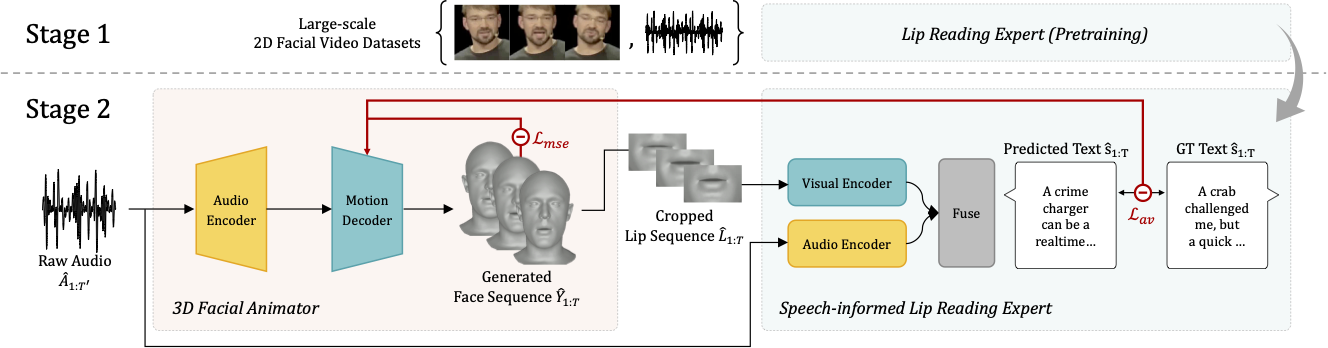
[C2] Enhancing Speech-Driven 3D Facial Animation with Audio-Visual Guidance from Lip Reading Expert
Han EunGi*, Oh Hyun-Bin*, Kim Sung-Bin, Corentin Nivelet Etcheberry, Suekyeong Nam, JangHoon Ju, Tae-Hyun Oh (*: equal contribution)
- We generate speech-synchronized lip movements in 3D facial animation with audio-visual lip reading expert.

[C1] MultiTalk: Enhancing 3D Talking Head Generation Across Languages with Multilingual Video Dataset
Kim Sung-Bin*, Lee Chae-Yeon*, Gihun Son*, Oh Hyun-Bin, JangHoon Ju, Suekyeong Nam, Tae-Hyun Oh
- We generate accurate 3D talking heads from multilingual speech.
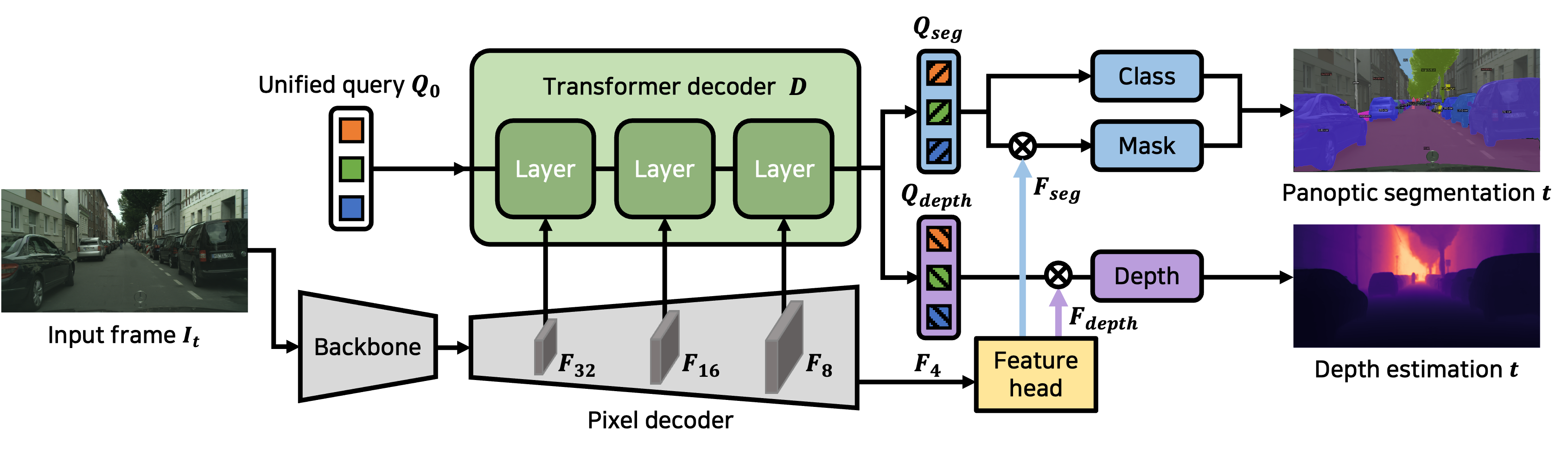
[J1] Uni-DVPS: Unified Model for Depth-Aware Video Panoptic Segmentation
Kim Ji-Yeon, Oh Hyun-Bin, Kwon Byung-Ki, Dahun Kim, Yongjin Kwon, Tae-Hyun Oh
- We present Uni-DVPS, a unified multi-task model for Depth-aware Video Panoptic Segmentation (DVPS).
- Oral presentation at IROS 2024
- Short version at CVPRW 2023 ‘Vision-Centric Autonomous Driving (VCAD)’ Workshop.
🎖 Honors and Awards
- 2025: Best Paper Award, IPIU
- 2024: Best Paper Award, KRoC
- 2023: Best Paper Award, IPIU
- 2021: Summa Cum Laude, Chung-Ang University
- 2021: Department Honors Scholarship, Chung-Ang University
- 2018: Science Scholarship, Suwon Municipal Scholarship Foundation
- 2017: Department Honors Scholarship, Chung-Ang University
📖 Educations
- 2022.03 - Present: Integrated Ph.D. in Electrical Engineering, Pohang University of Science and Technology (POSTECH), Pohang, South Korea
- 2017.03 - 2021.08: B.S. in Physics & B.E. in Electrical Engineering, Chung-Ang University, Seoul, South Korea
- Summa Cum Laude
🫡 Academic Services
- Conference Reviewer: ACCV, CVPR
- Journal Reviewer: IJCV, Pattern Recognition
🧑🏫 Teaching Experiences
- 2023, NAVER Boostcamp AI Tech Computer Vision Track (5th, 6th)
- 2022, Introduction to Machine Learning (EECE454), POSTECH